In my last post, I showed you how to install Python and set up Stata to use Python. Now, we’re ready to use Python. There are three ways to use Python within Stata: calling Python interactively, including Python code in do-files and ado-files, and executing Python script files. Each is useful in different circumstances, so I will demonstrate all three. The examples are intentionally simple and somewhat silly. I’ll show you some more complex examples in future posts, but I want to keep things simple in this post. Read more…
Python integration is one of the most exciting features in Stata 16. There are thousands of free Python packages that you can use to access and process data from the Internet, visualize data, explore data using machine-learning algorithms, and much more. You can use these Python packages interactively within Stata or incorporate Python code into your do-files. And there are a growing number of community-contributed commands that have familiar, Stata-style syntax that use Python packages as the computational engine. But there are a few things that we must do before we can use Python in Stata. This blog post will show you how to set up Stata to use Python. Read more…
Apple recently announced that it will be transitioning from Intel processors to its own ARM architecture processors currently being called Apple Silicon. Stata has a long history of supporting Macs, which includes the transitions from Motorola to PowerPC processors, from MacOS Classic to MacOS X, and from PowerPC to Intel processors. We will be working to support the new Macs as they transition from Intel processors to Apple Silicon and will continue our support of Macs with Intel processors as well.
Whether you are a new user needing to import, clean, and prepare data for your first analysis in Stata or you are an experienced user hoping to learn new tricks for the most challenging tasks, this book is for you. You can jump straight to the section of the book that discusses the particular challenge you are facing. There you will find a clear explanation of how to approach the problem and illustrative examples to guide you. Read more…
I care about reproducible research. Anyone who has ever been a research assistant or tried to follow the path set by other researchers also cares. Sometimes, reproducing others’ results is a frustrating task; sometimes, it is outright impossible. Yet sometimes, it is satisfyingly simple. In my experience, reproducing results is easy when it involves a Stata do-file. I believe this is true even beyond my personal bias (I work for Stata and used the software regularly before that). A recent article published by the American Economic Association (AEA), Vilhuber, Turrito, and Welch (2020), shows that Stata is the preferred package among economists, and I believe reproducibility is a big reason why. Read more…
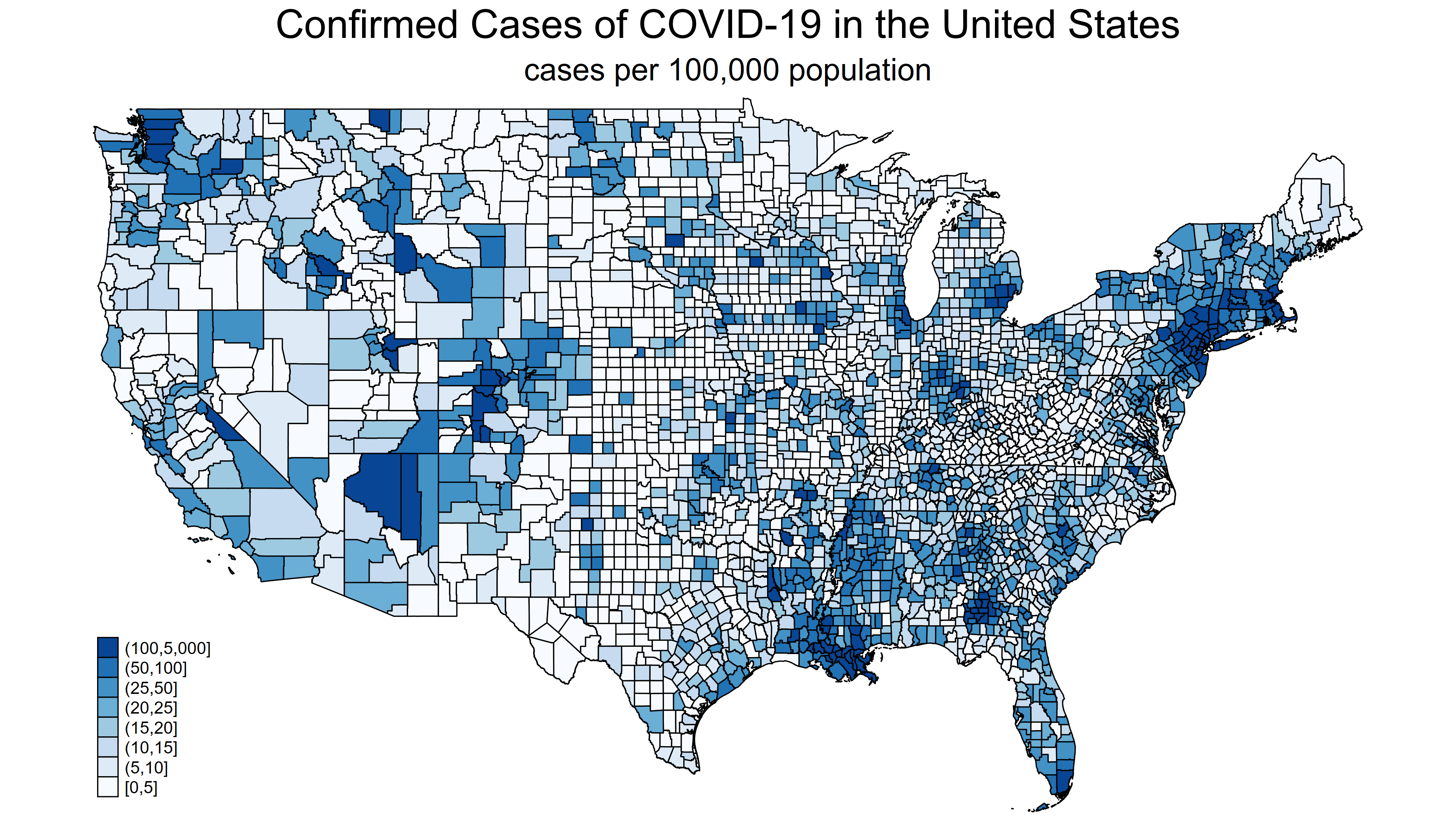
The video below shows the cumulative number of COVID-19 cases per 100,000 population for each county in the United States from January 22, 2020, through April 5, 2020. The map doesn’t change much until mid-March, when the virus starts to spread faster. Then, we can see when and where people are being infected. You can click on the “Play” icon on the video to play it and click on the icon on the bottom right to view the video in full-screen mode.
In my last post, we learned how to import the raw COVID-19 data from the Johns Hopkins GitHub repository and convert the raw data to time-series data. This post will demonstrate how to download raw data and create choropleth maps like figure 1.
Figure 1: Confirmed COVID-19 cases in United States adjusted for population size
In my last post, we learned how to import the raw COVID-19 data from the Johns Hopkins GitHub repository. This post will demonstrate how to convert the raw data to time-series data. We’ll also create some tables and graphs along the way. Read more…
In my last post, I mentioned that I did not want to distribute my covid19.ado file because “it could be rendered useless if or when Johns Hopkins changes its data”. I wrote that on March 19, 2020, and the data changed on March 23, 2020. This will likely happen again (and again, and again …). I may post updates in the future as the data change, but you may need to adapt sooner than I can post. So let’s see how we can update our code to adapt to the changing data. Read more…
Like many of you, I am working from home and checking the latest news on COVID-19 frequently. I see a lot of numbers and graphs, so I looked around for the “official data”. One of the best data sources I have found is at the GitHub website for Johns Hopkins Whiting School of Engineering Center for Systems Science and Engineering. The data for each day are stored in a separate file, so I wrote a little Stata command called covid19 to download, combine, save, and graph these data. Read more…