The aim of this blog is to describe two novel features introduced in Stata 18 (released in 2023): 1) framesets and 2) alias variables across frames. These features enable Stata to deal with a multiplicity of potentially very large datasets efficiently and conveniently. Framesets allow you to bundle, save on file, and load in memory a set of related frames that hold datasets. Alias variables allow you to access variables in other frames as if they were part of the current frame, with very little memory overhead. Read more…
Working with Wharton Research Data Services (WRDS) data in Stata is now even easier. I previously wrote about accessing WRDS data via ODBC. With Stata 17, using JDBC makes configuring WRDS and Stata even easier—and the steps to configure are the same across all operating systems. Whether you download WRDS data to your local machine or work in the cloud, the command to use in Stata for JDBC is jdbc. Read more…
The video below shows the cumulative number of COVID-19 cases per 100,000 population for each county in the United States from January 22, 2020, through April 5, 2020. The map doesn’t change much until mid-March, when the virus starts to spread faster. Then, we can see when and where people are being infected. You can click on the “Play” icon on the video to play it and click on the icon on the bottom right to view the video in full-screen mode.
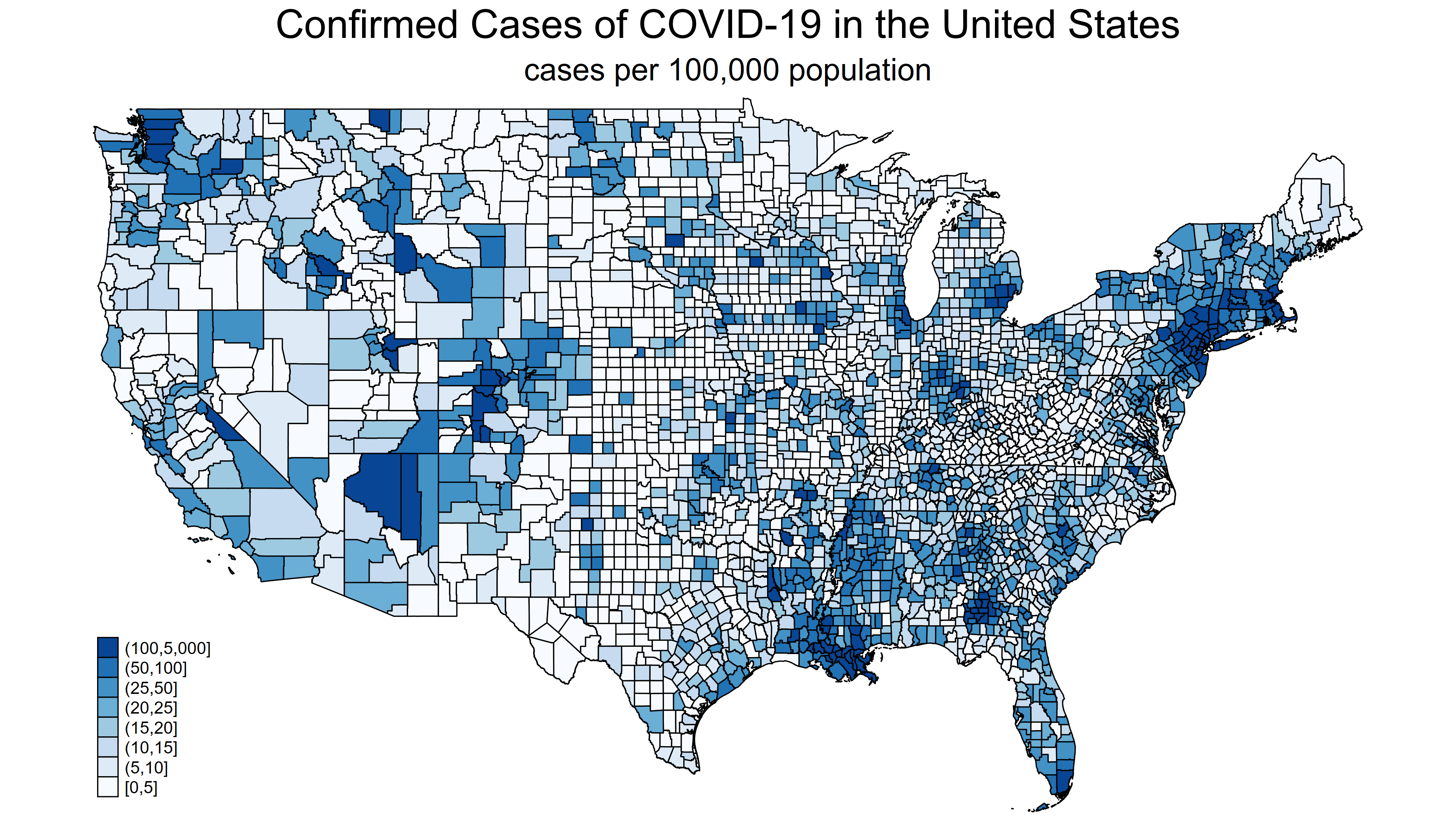
In my last post, we learned how to import the raw COVID-19 data from the Johns Hopkins GitHub repository and convert the raw data to time-series data. This post will demonstrate how to download raw data and create choropleth maps like figure 1.
Figure 1: Confirmed COVID-19 cases in United States adjusted for population size
In my last post, we learned how to import the raw COVID-19 data from the Johns Hopkins GitHub repository. This post will demonstrate how to convert the raw data to time-series data. We’ll also create some tables and graphs along the way. Read more…
In my last post, I mentioned that I did not want to distribute my covid19.ado file because “it could be rendered useless if or when Johns Hopkins changes its data”. I wrote that on March 19, 2020, and the data changed on March 23, 2020. This will likely happen again (and again, and again …). I may post updates in the future as the data change, but you may need to adapt sooner than I can post. So let’s see how we can update our code to adapt to the changing data. Read more…
Like many of you, I am working from home and checking the latest news on COVID-19 frequently. I see a lot of numbers and graphs, so I looked around for the “official data”. One of the best data sources I have found is at the GitHub website for Johns Hopkins Whiting School of Engineering Center for Systems Science and Engineering. The data for each day are stored in a separate file, so I wrote a little Stata command called covid19 to download, combine, save, and graph these data. Read more…
As of November 2019, this command no longer works because of https://stats.nba.com restrictions.
Since our intern, Chris Hassell, finished nfl2stata earlier than expected, he went ahead and created another command to web scrape https://stats.nba.com for data on the NBA. The command is nba2stata. To install the command type
net install http://www.stata.com/users/kcrow/nba2stata, replace
The nfl2stata command no longer works due to website changes.
Football season is around the corner, and I could not be more excited. We have a pretty competitive StataCorp fantasy football league. I’m always looking for an edge in our league, so I challenged one of our interns, Chris Hassell, to write a command to web scrape http://www.nfl.com for data on the NFL. The new command is nfl2stata. To install the command, type
net install http://www.stata.com/users/kcrow/nfl2stata, replace
It’s summer time, which means we have interns working at StataCorp again. Our newest intern, Chris Hassell, was tasked with updating my community-contributed command tab2xl with most of the suggestions that blog readers left in the comments. Chris updated tab2xl and wrote tab2docx, which writes a tabulation table to a Word file using the putdocx command. Read more…