This post shows how to create animated graphics that illustrate the spatial spillover effects generated by a spatial autoregressive (SAR) model. After reading this post, you could create an animated graph like the following.
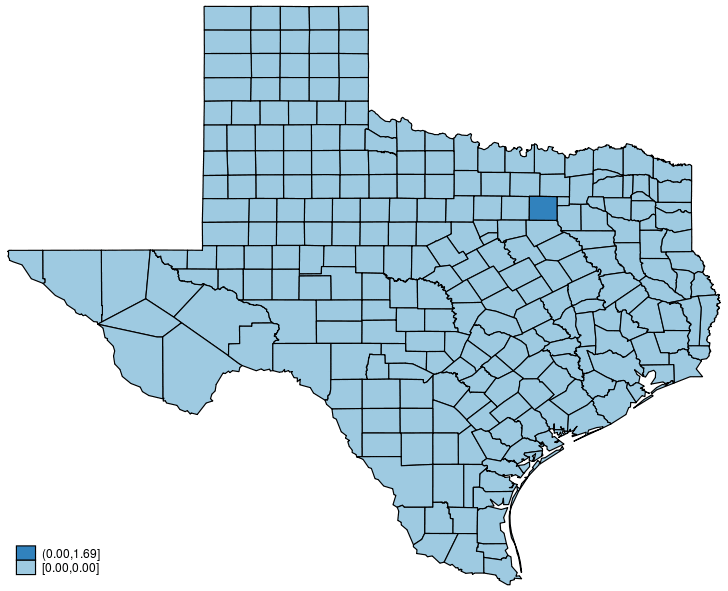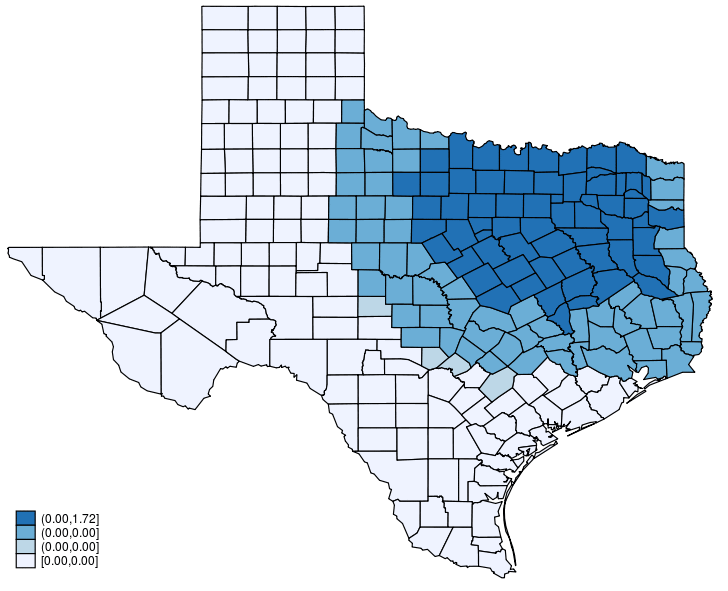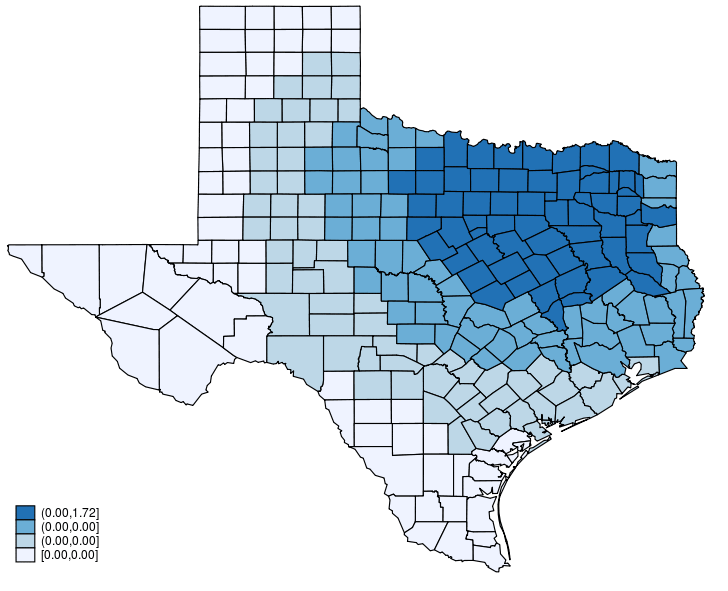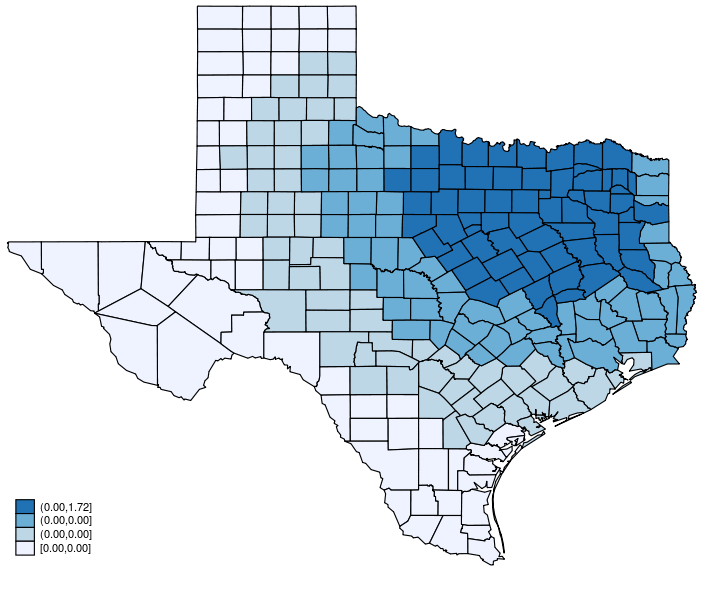
This post is organized as follows. First, I estimate the parameters of a SAR model. Second, I show why a SAR model can produce spatial spillover effects. Finally, I show how to create an animated graph that illustrates the spatial spillover effects. Read more…
“The book that Stata programmers have been waiting for” is how the Stata Press describes my new book on Mata, the full title of which is
The Mata Book: A Book for Serious Programmers and Those Who Want to Be
The Stata Press took its cue from me in claiming that it this the book you have been waiting for, although I was less presumptuous in the introduction:
This book is for you if you have tried to learn Mata by reading the Mata Reference Manual and failed. You are not alone. Though the manual describes the parts of Mata, it never gets around to telling you what Mata is, what is special about Mata, what you might do with Mata, or even how Mata’s parts fit together. This book does that.
I’m excited about the book, but for a while I despaired of ever completing it. I started and stopped four times. I stopped because the drafts were boring. Read more…
This post is the fourth in a series that illustrates how to plug code written in another language (like C, C++, or Java) into Stata. This technique is known as writing a plugin or as writing a dynamic-link library (DLL) for Stata.
In this post, I write a plugin in Java that implements the calculations performed by mymean_work() in mymean11.ado, discussed in Programming an estimation command in Stata: Preparing to write a plugin, and I assume that you are familiar with that material.
This post is analogous to Programming an estimation command in Stata: Writing a C plugin and to Programming an estimation command in Stata: Writing a C++ plugin. The differences are due to the plugin code being in Java instead of C or C++. I do not assume that you are familiar with the material in those posts, and much of that material is repeated here.
This is the 32nd post in the series Programming an estimation command in Stata. See Programming an estimation command in Stata: A map to posted entries for a map to all the posts in this series. Read more…
This post is the third in a series that illustrates how to plug code written in another language (like C, C++, or Java) into Stata. This technique is known as writing a plugin or as writing a dynamic-link library (DLL) for Stata.
In this post, I write a plugin in C++ that implements the calculations performed by mymean_work() in mymean11.ado, discussed in Programming an estimation command in Stata: Preparing to write a plugin. I assume that you are familiar with the material in that post.
This post is analogous to Programming an estimation command in Stata: Writing a C plugin. The differences are due to the plugin code being in C++ instead of C. I do not assume that you are familiar with the material in that post, and you will find much of it repeated here.
This is the 31st post in the series Programming an estimation command in Stata. I recommend that you start at the beginning. See Programming an estimation command in Stata: A map to posted entries for a map to all the posts in this series. Read more…
This post is the second in a series that illustrates how to plug code written in another language (like C, C++, or Java) into Stata. This technique is known as writing a plugin or as writing a dynamic-link library (DLL) for Stata.
In this post, I write a plugin in C that implements the calculations performed by mymean_work() in mymean11.ado, discussed in Programming an estimation command in Stata: Preparing to write a plugin. I assume that you are familiar with the material in that post.
This is the 30th post in the series Programming an estimation command in Stata. See Programming an estimation command in Stata: A map to posted entries for a map to all the posts in this series. Read more…
This post is the first in a series that illustrates how to plug code written in another language (like C, C++, or Java) into Stata. This technique is known as writing a plugin or as writing a dynamic-link library (DLL) for Stata.
Plugins can be written for any task, including data management, graphical analysis, or statistical estimation. Per the theme of this series, I discuss plugins for estimation commands.
In this post, I discuss the tradeoffs of writing a plugin, and I discuss a simple program whose calculations I will replace with plugins in subsequent posts.
This is the 29th post in the series Programming an estimation command in Stata. See Programming an estimation command in Stata: A map to posted entries for a map to all the posts in this series. Read more…
As of 2018, this command no longer works due to Facebook API restrictions.
In a previous post, we released a new command to import Twitter data into Stata. We have now added another new command, facebook2stata, that imports Facebook data. To install facebook2stata, type
net install https://www.stata.com/users/kcrow/facebook2stata, replace
Read more…
Data management and data cleaning are critically important steps in any data analysis. Many of us learned this lesson the hard way. Have you ever fit a model that includes age as a covariate and forgotten to convert the missing value codes of -99 to missing values? I have. Or maybe you overlooked a data entry error that resulted in an age of 354 that should have been 54. I’ve done that too. Careful data management and cleaning can help us avoid these kinds of embarrassing mistakes.
I recently recorded a series of data management videos for the Stata Youtube Channel. You can click on the links below to watch the videos. I included topics that I think are important, but the list is far from exhaustive. If you would like to see videos on additional topics, please leave your suggestion in the comments below.
Data management playlist
You can learn more about these topics and many others in the Data Management Reference Manual.
You have a model that is nonlinear in the parameters. Perhaps it is a model of tree growth and therefore asymptotes to a maximum value. Perhaps it is a model of serum concentrations of a drug that rise rapidly to a peak concentration and then decay exponentially. Easy enough, use nonlinear regression ([R] nl) to fit your model. But … what if you have repeated measures for each tree or repeated blood serum levels for each patient? You might want to account for the correlation within tree or patient. You might even believe that each tree has its own asymptotic growth. You need nonlinear mixed-effects models—also called nonlinear hierarchical models or nonlinear multilevel models. Read more…
In my previous post, I talked about how to combine the Java library Twitter4J and Stata’s Java function Interface using Eclipse to create a helloWorld plugin. Now, I want to talk about how to call Twitter4j member functions to connect to Twitter REST API, return Twitter data, and load that data into Stata using the Stata SFI. Read more…